I’ve read countless articles and posts in my quest to understand the nuances of storage.
I’ll add the useful links I have now, and will update this post over time.
General
These first three posts cover many aspects of storage, so they’re a great start:
- http://www.networkcomputing.com/storage-networking-management/ssds-and-understanding-storage-performan/240004957
- http://www.networkcomputing.com/servers-storage/more-on-performance-metrics-the-relation/240005213
- http://www.networkcomputing.com/servers-storage/of-iops-and-raid-how-raid-affects-applic/240007859
Some important excerpts from above:
For databases and other random-access applications, throughput is much less important than I/O latency and the number of I/O operations per second (IOPS) the storage system can perform.
So does it make sense to add SSDs to a storage system with 1-Gbps connections? Sure does, if that storage system is going to run a database application like Oracle, MySQL or even Exchange, all of which manage data in small pages. To saturate even one 1-Gbps connection would take 15,000 8K IOPS, while a 12-drive SATA system without SSD would struggle to deliver 1,500.
This relationship between IOPS and latency is one very good reason to pay more attention to published results from benchmarks like JetStress, TPC-C and SPC-1 rather than simple performance tests like Iometer.
In the real world many RAID controllers don’t have the bandwidth or CPU horsepower to achieve total parallelization, so a 14+1 RAID 5 set will do small I/Os significantly slower than a 5+1 RAID set.
While an oversimplification–as all rules of thumb are–the storage admin’s rule of thumb to use RAID 10 for random I/O workloads and parity RAID for sequential workloads does hold water. Of course, sequential workloads, other than backups, are becoming rare in today’s virtualized data center.
IOPS
- http://recoverymonkey.org/2012/07/26/an-explanation-of-iops-and-latency/
IOPS numbers by themselves are meaningless and should be treated as such. Without additional metrics such as latency, read vs write % and I/O size (to name a few), an IOPS number is useless. - http://blog.synology.com/blog/?p=146
Performance Capacity Planning Explained. - http://www.techrepublic.com/blog/datacenter/calculate-iops-in-a-storage-array/2182
- Published IOPS calculations aren’t the end-all be-all of storage characteristics. Vendors often measure IOPS under only the best conditions, so it’s up to you to verify the information and make sure the solution meets the needs of your environment.
- IOPS calculations vary wildly based on the kind of workload being handled. In general, there are three performance categories related to IOPS: random performance, sequential performance, and a combination of the two, which is measured when you assess random and sequential performance at the same time.
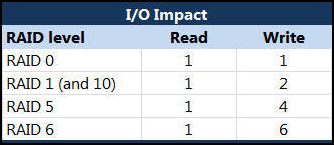
- The IOPS RAID Penalty

- http://www.yellow-bricks.com/2009/12/23/iops/
I found a formula and tweaked it a bit so that it fits our needs:
(TOTAL IOps × % READ)+ ((TOTAL IOps × % WRITE) ×RAID Penalty)
So for RAID-5 and for instance a VM which produces 1000 IOps and has 40% reads and 60% writes:
(1000 x 0.4) + ((1000 x 0.6) x 4) = 400 + 2400 = 2800 IO’s
The 1000 IOps this VM produces actually results in 2800 IO’s on the backend of the array, this makes you think doesn’t it?
RAID
- http://www.acnc.com/raidedu/10
Useful animation showing RAID 10 in action: RAID 10: Very High Reliability Combined with High Performance - http://www.acnc.com/raidedu/5
Useful animation showing RAID 5 in action: RAID 5: Independent Data Disks with Distributed Parity Blocks - http://www.datamation.com/netsys/article.php/3842246/The-Agony-and-Ecstasy-of-RAID.htm
Backup and fault tolerance are very different conceptually (you will always need backups). Backup is designed to allow you to recover after a disaster has occurred. Fault tolerance is designed to lessen the chance of disaster. - http://www.miracleas.com/BAARF/RAID5_versus_RAID10.txt
Now if a drive in the RAID5 array dies, is removed, or is shut off data is returned by reading the blocks from the remaining drives and calculating the missing data using the parity, assuming the defunct drive is not the parity block drive for that RAID block. Note that it takes 4 physical reads to replace the missing disk block (for a 5 drive array) for four out of every five disk blocks leading to a 64% performance degradation until the problem is discovered and a new drive can be mapped in to begin recovery. Performance is degraded further during recovery because all drives are being actively accessed in order to rebuild the replacement drive (see below).If a drive in the RAID10 array dies data is returned from its mirror drive in a single read with only minor (6.25% on average for a 4 pair array as a whole) performance reduction when two non-contiguous blocks are needed from the damaged pair (since the two blocks cannot be read in parallel from both drives) and none otherwise.During recovery, read performance for a RAID5 array is degraded by as much as 80%. Some advanced arrays let you configure the preference more toward recovery or toward performance. However, doing so will increase recovery time and increase the likelihood of losing a second drive in the array before recovery completes resulting in catastrophic data loss. RAID10 on the other hand will only be recovering one drive out of 4 or more pairs with performance ONLY of reads from the recovering pair degraded making the performance hit to the array overall only about 20%! Plus there is no parity calculation time used during recovery – it’s a straight data copy. - http://en.wikipedia.org/wiki/RAID#Problems_with_RAID
Increasing drive capacities and large RAID 5 redundancy groups have led to an increasing inability to successfully rebuild a RAID group after a drive failure because an unrecoverable sector is found on the remaining drives. Parity schemes such as RAID 5 when rebuilding are particularly prone to the effects of UREs as they will affect not only the sector where they occur but also reconstructed blocks using that sector for parity computation; typically an URE during a RAID 5 rebuild will lead to a complete rebuild failure.Double protection schemes such as RAID 6 are attempting to address this issue, but suffer from a very high write penalty. Non-parity (mirrored) schemes such as RAID 10 have a lower risk from UREs.Even though individual drives’ mean time between failure (MTBF) have increased over time, this increase has not kept pace with the increased storage capacity of the drives. The time to rebuild the array after a single drive failure, as well as the chance of a second failure during a rebuild, have increased over time.As of August 2012, Dell, Hitachi, Seagate, Netapp, EMC, HDS, SUN Fishworks and IBM have current advisories against the use of RAID 5 with high capacity drives and in large arrays. - http://community.spiceworks.com/topic/262196-one-big-raid-10-the-new-standard-in-server-storage
One Big RAID 10: The new standard in server storage - http://community.spiceworks.com/topic/100620-raid-5-or-1-0-aka-10
Good discussion comparing RAID 5 and RAID10.
Performance
I found this useful post showing the relationship between RAID, IOPS and Bandwidth: http://www.qdpma.com/Storage/HP_P2000.html
| 2000 Array Performance | P2000 G3 FC | P2000 G3 SAS |
P2000 G3 10GbE iSCSI | P2000 G3 1GbE iSCSI |
| Protocol (host connect) | 8 Gb Fibre Channel |
6 Gb SAS |
10Gb Ethernet |
1 Gb Ethernet |
| 2000 RAID 10 Performance Results | ||||
| Sequential Reads MB/s | 1,650 | 1,650 | 1,600 | 550 |
| Sequential Writes MB/s | 850 | 850 | 800 | 525 |
| Random Mix IOPs 60/40 read/write | 20,500 | 23,500 | 18,500 | 17,200 |
| 2000 RAID 5 Performance Results | ||||
| Sequential Reads MB/s | 1,650 | 1,650 | 1,600 | 550 |
| Sequential Writes MB/s | 1,300 | 1,350 | 1,000 | 525 |
| Random Mix IOPs 60/40 read/write | 14,000 | 16,000 | 12,500 | 9,400 |
| 2000 RAID 6 Performance Results | ||||
| Sequential Reads MB/s | 1,650 | 1,650 | 1,600 | 550 |
| Sequential Writes MB/s | 1,300 | 1,100 | 1,000 | 525 |
| Random Mix IOPs 60/40 read/write | 8,300 | 9,800 | 7,500 | 5,600 |
| Refer to the paper titled “Upgrading the HP MSA2000 (G1 or G2) to the P2000 G3 MSA “, available in the Resource Library at: www.hp.com/go/p2000. | ||||
Reliability
- http://www.networkcomputing.com/servers-storage/the-truth-about-storage-reliability/229609355
- http://www.smbitjournal.com/2012/05/when-no-redundancy-is-more-reliable/
Misc
- http://www.smbitjournal.com/2012/12/the-history-of-array-splitting/
- http://www.smbitjournal.com/2012/08/choosing-a-storage-type/
Tools
- IOPS Calculator: http://www.wmarow.com/strcalc/
- RAID Calculator: http://www.wmarow.com/strcalc/raidslider.html and http://www.wolframalpha.com/input/?i=RAID+calculator
- Array Estimator: http://www.wmarow.com/strcalc/goals.html
Conclusion
We should not be making buying decisions based solely on capacity
Yes, RAID5 will give you a better price per GB, but what’s the cost to the business when an array that’s rebuilding is running as much as 80% slower. Even worse, what’s the cost to the business when you get a double drive failure, lose your whole array, then realise backups will take an age to restore, if at all.
Art S. Kagel sums this up nicely:
What is the cost of overtime, wear and tear on the technicians, DBAs, managers, and customers of even a recovery scare? What is the cost of reduced performance and possibly reduced customer satisfaction? Finally what is the cost of lost business if data is unrecoverable? I maintain that the drives are FAR cheaper!
We should not be making buying decisions based solely on bandwidth
Bandwidth is important for sequential reads and write, but the majority of workloads in a modern virtual infrastructure consist of tiny random IO.
We should benchmark our current systems to record the workload patterns, noting the average read/write percentage split, average and peak IOPS, and block size (eg. 4KB, 8KB etc).
Given these metrics, we can specify a storage system to meet these needs.
